Alex Bikfalvi
YTCrawler Release 1
The YouTube Crawler is a project in progress and the software on this page is pre-release and subject to change. There are no guarantees for this software and you can use it on your own risk. The YouTube Crawler is free software and is licensed under the terms of GNU General Public License.
Contents
- Architecture overview
- Database clustering
- Using the crawler
- Understanding video feeds
- Setup guide
- Code information
- Download software
I. Architecture Overview
The YouTube Crawler is a software application that can be used to crawl video information from YouTube. The crawler can capture both static information such as videos' title, author, duration, publishing date, etc, as well as dynamic information such as videos' view count, number of comments, rating, etc. Because static and dynamic video information is usually recorded in a different manner (is sufficient to crawl static data only once, whereas dynamic data should be crawled periodically), the YouTube Crawler has three components.
The crawler uses an Oracle database to store the crawled video information. The following figure illustrates the principles of the design.
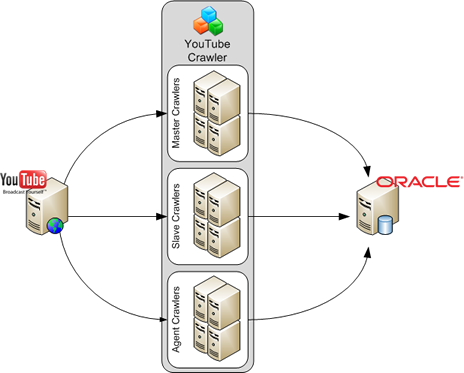
The Master Crawler
The master is responsible for initial crawling of YouTube videos and recording the static video information. Video discovery is acheieved using any of the standard or category based YouTube video feeds. For example, standard feeds include most popular, most recent, most viewed videos, etc; category-based feeds include music, people, games, howto, etc. You can configure any video feed combination for the master crawling.
In addition, for a crawling deployment, you can use any number of masters in order to load-balance the crawling activity. If you need to identify the data crawled by an individual master, you can preconfigure each master with a unique identifier that will be stored in the database along with the video information.
The Slave Crawler
The slave is used to crawl dynamic video data. Like the master, multiple instances of the slave can be used at the same time to load-balance the crawling activity, each slave being assigned a unique identifier. For this purpose, each master should be configured with the identifiers of the available slaves, and will automatically assign new crawled videos in a balanced manner.
Tip: You can provide redundancy in the crawled data, by assigning the same identifier to two or more slaves.
The Processing Agent
This feature is under development.
The agent has the role of processing live the crawled data. Such processing will include assigning different crawling schedule to videos that meet certain criteria. For example, in a deployment scenario with two slaves, one can be configured to crawl every hour dynamic information for videos that have at least one view per day, while the second slave can be configured to crawl every six hours dynamic information for videos that have less than one view per day. Using the crawled data, the agent will verify periodically the change in view count and can assign each video to the corresponding slave.
Other tasks of the agent will be to verify the crawled data, eliminate errors, perform additional post-processing.
II. Database Clustering
This is a new feature that will be made available in release 2.
III. Using the Crawler
The master, the slave and the processing agent are implemented within the same software application. However, you can use any number of running instances, on any number of computers, to accomodate the necessary number of masters, slaves and processing agents for your scenario.
Typically, you must follow these steps to setup a crawling scenario:
- Configure the connection to the database
- Configure the master and the slave
- Setup the video categories to crawl, if necessary
- Change the crawling order for video feeds, if necessary
- Start the master
- Start the slave
- Inspect your results during or after the crawling
Configure the Connection to the Database
To configure the connection to the Oracle database, you have to enter the name of the database (see the setup section for details), username and password. You can test the connection by connecting to the database at any time. However, establishing an initial connection is not necessary, as the software will automatically connect whenever needed.
)
Configure the Master and the Slave
Before you start the crawling you must configure the following information:
- General crawler parameters: maximum number videos and the number of slaves
- Database parameters: the name of the database tables you use for crawling
- Video discovery parameters: if the base and global video feeds are crawled (see video feeds for more information)
- Video feeds: specify which of the standard feeds are crawled
- Master configuration: the crawling period, default video schedule (whether the video is active, i.e. crawled by a slave, or not), master identifier, maximum number of videos for one crawl, the collection of slaves (the master will assign the videos to them in a uniform manner)
- Slave configuration: the crawling period, a number of crawling filters, slave identifier, number of parallel crawling operations, number of retries in case of errors
)
)
)
)
Setup Video Categories
Optional, you can configure any selection of video categories (see video feeds for more information).
)
Change Video Feeds
Optional, you can also modify the order of the video feeds (see video feeds for more information).
)
Start the Master
Start the master crawler. The master will run periodically with the setup schedule until stopped.
)
Start the Slave
Start the slave crawler. The slave will run periodically with the setup schedule until stopped. To enhance performance (i.e. increase the crawling speed), the slave will spawn the configured number of parallel threads to perform the crawling.
)
View Your Data
This feature may be under future development.
You can use the YouTube Crawler to analyze your data, either in real time during the crawling, or at the end, after the crawling has completed. Currently, you can view the following information:
- The static information of all videos collected by the master (a number of filters is available to sort out only the information of interest)
- The dynamic snapshots for the videos, collected by the slave
- Statistical information on the number of crawled videos over the crawling period
- Statistical information on the minimum and maximum view count for crawled videos
Tip: You can automatically locate the dynamic data snapshots for a video by using the 'View snapshots' button.
)
)
)
)
IV. Understanding Video Feeds
For the master crawling, you have to configure video feeds. The YouTube Crawler uses two main types of videos feeds: standard feeds and category feeds. Standard feeds are associated with certain classes of videos, such as the most popular, the most views, the most recent, etc. The following table shows the set of standard feeds currently supported by YouTube and by the YouTube Crawler (see here additional details).
| Feed | Information |
|---|---|
| Top rated | URL: http://gdata.youtube.com/feeds/api/standardfeeds/top_rated Description: This feed contains the most highly rated YouTube videos. |
| Top favorites | URL: http://gdata.youtube.com/feeds/api/standardfeeds/top_favorites Description: This feed contains videos most frequently flagged as favorite videos. |
| Most viewed | URL: http://gdata.youtube.com/feeds/api/standardfeeds/most_viewed Description: This feed contains the most frequently watched YouTube videos. |
| Most popular | URL: http://gdata.youtube.com/feeds/api/standardfeeds/most_popular Description: This feed contains the most popular YouTube videos, selected using an algorithm that combines many different signals to determine overall popularity. |
| Most recent | URL: http://gdata.youtube.com/feeds/api/standardfeeds/most_recent Description: This feed contains the videos most recently submitted to YouTube. |
| Most discussed | URL: http://gdata.youtube.com/feeds/api/standardfeeds/most_discussed Description: This feed contains the YouTube videos that have received the most comments. |
| Most responded | URL: http://gdata.youtube.com/feeds/api/standardfeeds/most_responded Description: This feed contains YouTube videos that receive the most video responses. |
| Recently featured | URL: http://gdata.youtube.com/feeds/api/standardfeeds/recently_featured Description: This feed contains videos recently featured on the YouTube home page or featured videos tab. |
| Videos for mobile phones | URL: http://gdata.youtube.com/feeds/api/standardfeeds/watch_on_mobile Description: This feed contains videos suitable for playback on mobile devices. |
In addition to these standard feeds there exists a global videos feed:
| Feed | Information |
|---|---|
| Global | URL: http://gdata.youtube.com/feeds/api/videos |
Category feeds are defined by the user, based on the category keywords the user selects. In practice, these feeds should match actual video categories from YouTube, but you are allowed to define any combination of categories. The following table contains some examples of category feeds.
| Category | Information |
|---|---|
| Movies | URL: http://gdata.youtube.com/feeds/api/videos/-/Movies |
| Entertainment | URL: http://gdata.youtube.com/feeds/api/videos/-/Entertainment |
| Music | URL: http://gdata.youtube.com/feeds/api/videos/-/Music |
For crawling you are allowed to every combination of standard and category feeds. For instance, if you select the standard feeds most popular and most recent, with the categories Movies and Music, the YouTube Crawler will crawl the following categories:
| Category | Information |
|---|---|
| Most popular movies | URL: http://gdata.youtube.com/feeds/api/standardfeeds/most_popular/-/Movies |
| Most popular music | URL: http://gdata.youtube.com/feeds/api/standardfeeds/most_popular/-/Music |
| Most recent movies | URL: http://gdata.youtube.com/feeds/api/standardfeeds/most_recent/-/Movies |
| Most recent music | URL: http://gdata.youtube.com/feeds/api/standardfeeds/most_recent/-/Music |
In addition, you may also select to crawl the global feed for the selected standard feeds, which will add the following feeds to the crawling:
| Category | Information |
|---|---|
| Most popular | URL: http://gdata.youtube.com/feeds/api/standardfeeds/most_popular |
| Most recent | URL: http://gdata.youtube.com/feeds/api/standardfeeds/most_recent |
Finally, you may also select to crawl the base feed for the selected categories, which will add the following feeds to the crawling:
| Category | Information |
|---|---|
| Movies | URL: http://gdata.youtube.com/feeds/api/videos/-/Movies |
| Music | URL: http://gdata.youtube.com/feeds/api/videos/-/Music |
V. Setup Guide
System Requirements
To install and run the YouTube Crawler, you need the following:
- Operating system: Microsoft Windows XP SP3 or newer
- Oracle Instant Client for Windows (you can download the client from Oracle, free of charge, subject to accepting the Oracle Technology Network license agreement)
- Microsoft .NET Framework 3.5 (contact me if you wish to run YouTube Crawler on an earlier version of .NET Framework)
In addition, you need an Oracle database. You can download from Oracle for Linux x86 or Windows, free of charge, Oracle 10g Express Edition, subject to accepting the Oracle Technology Network license agreement. For development purposes, you can also download Oracle 11g.
Install and Setup the Oracle Database
(this page is not a guidline for Oracle, although the process is straightforward most of the time; use Oracle documentation for this step)
Install and Setup the Oracle Client
(this page is not a guidline for Oracle, although the process is straightforward and easy most of the time; use Oracle documentation for this step)
An easy way to connect from a client to an Oracle database is to configure and use TNS names, by modifying (or creating if necessary) the tnsnames.ora file in the Network/Admin folder of your installation. A sample file is usually available in the Samples subfolder. For example, your tnsnames.ora file should look something like this:
my_database = ( DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = database_IP_address)(PORT = database_port)) (CONNECT_DATA = (SERVER = DEDICATED)(SERVICE_NAME = database_name)) )
Usually, the port is 1521. You use my_database as the database name in the YouTube Crawler.
Create the Database Tables
The YouTube Crawler uses two tables, one for static videos data, one for dynamic snapshot data. The master writes information to the videos table, the slave writes information to the snapshot table. The name of the tables can be customized and configured in the crawler. However, the structure of the tables is fixed in this version of the crawler.
The videos table contains the following columns:
| Videos Table | ||
|---|---|---|
| Column Name | Type | Description |
| ID | CHAR (11) | YouTube video identifier |
| TITLE | VARCHAR2 (256) | Video title |
| AUTHOR | VARCHAR2 (256) | Video author |
| DURATION | INTEGER | Video duration in seconds |
| CATEGORY | VARCHAR2 (256) | Video category |
| PUBLISHED | DATE | Video published date/time |
| VIEWS | INTEGER | Number of views at the time of crawling |
| COMMENTS | INTEGER | Number of comments at the time of crawling |
| RATING | NUMBER (20,10) | Rating at the time of crawling |
| CRAWL_MASTER | INTEGER | The identifier of the master |
| CRAWL_TYPE | INTEGER | The crawling type (see below) |
| CRAWL_SLAVE | INTEGER | The identifier of the assigned slave |
| CRAWL_SCHEDULE | INTEGER | The type of slave crawling schedule: active or inactive |
| CRAWL_STRING | VARCHAR2 (256) | The crawling string (see below) |
| CRAWL_ERRORS | INTEGER | The number of crawling errors (see below) |
| CRAWL_ERROR | INTEGER | The crawling error (see below) |
| CRAWL_FIRST | DATE | The date/time of the first crawling |
| CRAWL_LAST | DATE | The date/time of the last crawling |
Note 1: If a video is crawled by a master (or multiple masters) several times, the original information is always kept, except for the CRAWL_LAST field, which is updated with the time of the last crawl.
Note 2: The CRAWL_TYPE field is always zero (0) in the pre-release version of the YouTube Crawler. The value represents feed crawling, which is the only option available at this time. For the release version, the YouTube Crawler will also suport crawling related videos, response videos, user subscribed videos, user favorite videos, user playlists videos. The CRAWL_TYPE field will have different values for these types of crawling.
Note 3: The CRAWL_STRING field contains the feed URL used to crawl the video, in the pre-release version of the YouTube Crawler that supports only feed crawling (type 0). For the release version, in addition the CRAWL_STRING field will contain the identifier of the video used to crawl related and response videos, and the username used to crawl subscribed, favorite and playlist videos.
Note 4: The CRAWL_ERRORS field indicates the number of video parameters that were missing in the YouTube response.
Note 5: The CRAWL_ERROR field indicates the video parameters that were missing in the YouTube response. The value of this field is a binary map to all video parameters except the video identifier, as indicated by the following table (0 indicates success, 1 indicates error):
| Bit from LSB | Missing Video Parameter |
|---|---|
| 0 | Title |
| 1 | Author |
| 2 | Duration |
| 3 | Category |
| 4 | Publised |
| 5 | Views |
| 6 | Comments |
| 7 | Rating |
The snapshot table contains the following columns:
| Snapshots Table | ||
|---|---|---|
| Column Name | Type | Description |
| TIMESTAMP | DATE | The date/time of the crawling |
| VIDEO | CHAR (11) | YouTube video indentifier |
| VIEWS | INTEGER | Number of views at the time of crawling |
| COMMENTS | INTEGER | Number of comments at the time of crawling |
| RATING | NUMBER (20,10) | Rating at the time of crawling |
| SLAVE | INTEGER | The identifier of the slave |
| ERRORS | INTEGER | The number of crawling errors (see below) |
| ERROR | INTEGER | The crawling error (see below) |
| RETRIES | INTEGER | The number of retries (see below) |
Note 1: The CRAWL_ERRORS field indicates the number of video parameters that were missing in the YouTube response.
Note 2: The CRAWL_ERROR field indicates the information that is missing in the YouTube response. The value of this field is a binary map to the missing information, as indicated by the following table (0 indicates success, 1 indicates error):
| Bit from LSB | Missing Video Information |
|---|---|
| 0 | All information: YouTube did not return a response to the crawling request. When this bit is set to one (1), all other bits are set to zero (0), and the number of errors is set to one (1). |
| 1 | Views |
| 2 | Comments |
| 3 | Rating |
Note 3: When any of the video parameters or the video itself was missing in the YouTube response, the slave will automatically retry a limited number of times (by default, 2) to crawl the video during the same crawling session. The RETRIES field indicates the number of retries.
Install YouTube Crawler
Download and use the setup MSI file to install YouTube Crawler on your computer. The setup program should detect any dependencies that are missing and you will be prompted to install them. Once you complete this step you can start YouTube Crawler and you are good to go.
VI. Code Information
Code information is not yet availabe for the pre-release version.
VII. Download Software
You can download the software installer for the pre-release version of YouTube Crawler.
Download installer (MSI/2.50 MB)
For the pre-release version, the code is not yet available for download. Contact me, if you wish to obtain the open source code from the latest development build.
Last updated: May 26, 2010